
Ein Hinweis über die staatenlose Ethereum -Initiative:
Die Forschungsaktivität hat sich in der zweiten Hälfte von 2020 (verständlicherweise) verlangsamt, da sich alle Mitwirkenden an das Leben auf der seltsamen Zeitleiste angepasst haben. Wenn sich das Ökosystem jedoch schrittweise näher an die Gelassenheit und das ETH1/ETH2 -Zusammenschluss bewegt, wird die staatenlose Ethereum -Arbeit immer relevanter und wirkungsvoller. Erwarten Sie in den kommenden Wochen eine umfangreichere staatenlose Ethereum-Retrospektive.
Lassen Sie uns noch einmal durch die Wiederholung rollen: Das ultimative Ziel des Staatlosen Ethereum ist es, die zu entfernen Erfordernis eines Ethereum -Knotens, um eine vollständige Kopie des aktualisierten Zustandstries jederzeit zu behalten und stattdessen die Zustandsänderungen auf ein (viel kleineres) Daten zu verlassen, das beweist, dass eine bestimmte Transaktion eine gültige Änderung vornimmt. Dies löst ein großes Problem für Ethereum; Ein Problem, das bisher nur durch eine verbesserte Client -Software weiter herausgedrängt wurde: Zustandswachstum.
Der Merkle -Beweis, der für ein Staatelo -Ethereum benötigt wird unverändert Zwischen den Hashes, die zu einer neuen gültigen staatlichen Wurzel gelangen müssen. Zeugen sind theoretisch viel kleiner als der vollständige Ethereum -Staat (der bestenfalls 6 Stunden dauert, um zu synchronisieren), aber sie sind immer noch viel größer als ein Block (der sich in nur wenigen Sekunden in das gesamte Netzwerk ausbreiten muss). Die Größe der Zeugen auszuweichen ist daher von größter Bedeutung, um das staatenlose Ethereum in minimaler Nutzung zu bringen.
Genau wie der Ethereum -Staat selbst stammt ein Großteil des zusätzlichen (digitalen) Gewichts in Zeugen aus Smart Contract Code. Wenn eine Transaktion einen bestimmten Vertrag anruft, muss der Zeuge standardmäßig den Vertrags -Bytecode einbeziehen In seiner Gesamtheit mit dem Zeugen. Code Merkelization ist eine allgemeine Technik, um die Belastung des intelligenten Vertragscodes in Zeugen zu verringern, sodass Vertragsanrufe nur die Codestücken einbeziehen müssen, die sie berühren, um ihre Gültigkeit nachzuweisen. Allein mit dieser Technik sehen wir möglicherweise eine erhebliche Verringerung des Zeugens, aber es gibt viele Details, die bei der Aufschlüsselung intelligenter Vertragscode in Byte-Größe-Stücke in Betracht gezogen werden müssen.
Was ist Bytecode?
Es gibt einige Kompromisse bei der Aufteilung des Vertrags-Bytecode. Die Frage, die wir irgendwann stellen müssen, ist: “Wie groß werden die Codebrocken sein?” – Aber im Moment schauen wir uns einen echten Bytecode in einem sehr einfachen intelligenten Vertrag an, nur um zu verstehen, was es ist:
pragma solidity >=0.4.22 <0.7.0; contract Storage { uint256 number; function store(uint256 num) public { number = num; } function retrieve() public view returns (uint256){ return number; } }
Wenn dieser einfache Speichervertrag zusammengestellt wird, wird er in den Maschinencode “Inside” der EVM ausgeführt. Hier sehen Sie denselben einfachen Speichervertrag, der oben gezeigt wurde, jedoch in einzelne EVM -Anweisungen (Opcodes) eingehalten wird:
PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH1 0xF JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST POP PUSH1 0x4 CALLDATASIZE LT PUSH1 0x32 JUMPI PUSH1 0x0 CALLDATALOAD PUSH1 0xE0 SHR DUP1 PUSH4 0x2E64CEC1 EQ PUSH1 0x37 JUMPI DUP1 PUSH4 0x6057361D EQ PUSH1 0x53 JUMPI JUMPDEST PUSH1 0x0 DUP1 REVERT JUMPDEST PUSH1 0x3D PUSH1 0x7E JUMP JUMPDEST PUSH1 0x40 MLOAD DUP1 DUP3 DUP2 MSTORE PUSH1 0x20 ADD SWAP2 POP POP PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 RETURN JUMPDEST PUSH1 0x7C PUSH1 0x4 DUP1 CALLDATASIZE SUB PUSH1 0x20 DUP2 LT ISZERO PUSH1 0x67 JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST DUP2 ADD SWAP1 DUP1 DUP1 CALLDATALOAD SWAP1 PUSH1 0x20 ADD SWAP1 SWAP3 SWAP2 SWAP1 POP POP POP PUSH1 0x87 JUMP JUMPDEST STOP JUMPDEST PUSH1 0x0 DUP1 SLOAD SWAP1 POP SWAP1 JUMP JUMPDEST DUP1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP POP JUMP INVALID LOG2 PUSH5 0x6970667358 0x22 SLT KECCAK256 DUP13 PUSH7 0x1368BFFE1FF61A 0x29 0x4C CALLER 0x1F 0x5C DUP8 PUSH18 0xA3F10C9539C716CF2DF6E04FC192E3906473 PUSH16 0x6C634300060600330000000000000000
Wie erklärt ein früherer BeitragDiese Opcode -Anweisungen sind die grundlegenden Operationen der Stack -Architektur der EVM. Sie definieren den einfachen Speichervertrag und alle Funktionen, die es enthält. Sie können diesen Vertrag als einen der Beispielverträge in der Remix IDE (Beachten Sie, dass der obige Maschinencode ein Beispiel für den Speicher ist. Nachdem es bereits eingesetzt wurdeund nicht die Ausgabe des Solidity Compiler, der einige zusätzliche Bootstrapping -Opcodes hat). Wenn Sie Ihre Augen nicht fokussieren und sich eine physische Stapelmaschine zusammen mit Schritt-für-Schritt-Berechnung auf Opcode-Karten vorstellen, können Sie in der Unschärfe des sich bewegenden Stapels fast die Umrisse von Funktionen sehen, die im Soliditätsvertrag festgelegt sind.
Wenn der Vertrag einen Nachrichtenaufruf erhält, wird dieser Code in jedem Ethereum -Knoten ausgeführt, das neue Blöcke im Netzwerk validiert. Um heute eine gültige Transaktion auf Ethereum einzureichen, benötigt man eine vollständige Kopie des Bytecode des Vertrags, da das Ausführen dieses Codes von Anfang bis Ende der einzige Weg ist, den (deterministischen) Ausgangszustand und den zugehörigen Hash zu erhalten.
Denken Sie daran, dass das Ethereum das Ethereum beabsichtigt, diese Anforderung zu ändern. Nehmen wir an, Sie möchten nur die Funktion aufrufen abrufen() Und nichts weiter. Die Logik, die beschreibt, dass die Funktion nur eine Teilmenge des gesamten Vertrags ist, und in diesem Fall benötigt das EVM nur zwei der von der Grundblöcke von Opcode -Anweisungen, um den gewünschten Wert zurückzugeben:
PUSH1 0x0 DUP1 SLOAD SWAP1 POP SWAP1 JUMP, JUMPDEST PUSH1 0x40 MLOAD DUP1 DUP3 DUP2 MSTORE PUSH1 0x20 ADD SWAP2 POP POP PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 RETURN
In dem staatenlosen Paradigma sollte ein Zeuge, als ein Zeuge den fehlenden Hashes des nicht touchierten Zustands anbietet, auch die fehlenden Hashes für nicht ausgeführte Maschinencode bereitstellen, sodass ein staatenloser Kunde den Teil des von ihm ausgeführten Vertrags nur verlangt.
Der Zeuge des Kodex
Intelligente Verträge in Ethereum leben an dem gleichen Ort wie externe Konten: als Blattknoten in der enormen Einwurzelstaaten-Trie. Verträge unterscheiden sich in vielerlei Hinsicht nicht von den externen Konten, die Menschen verwenden. Sie haben eine Adresse, können Transaktionen einreichen und ein Gleichgewicht aus Äther und jedem anderen Token halten. Vertragskonten sind jedoch etwas Besonderes, da sie ihre eigene Programmlogik (Code) oder einen Hash enthalten müssen. Ein weiterer zugehöriger Merkle-Patricia Trie, der genannt Storagetrie Hält alle Variablen oder anhaltenden Zustand, dass ein aktiver Vertrag während der Ausführung sein Geschäft durchführt.
Diese Visualisierung der Zeugen bietet einen guten Sinn dafür, wie wichtig Code Merklization bei der Verringerung der Größe der Zeugen sein könnte. Sehen Sie diesen riesigen Teil farbiger Quadrate und wie viel größer als alle anderen Elemente im Trie? Das ist eine einzige vollständige Portion Smart Contract Bytecode.
Daneben und etwas unten sind die Stücke persistierter Zustand in der Storagetriewie ERC20 Balance Mappings oder ERC721 Digital Item Ownerships. Da es sich beispielsweise um einen Zeugen und kein vollständiger Zustands -Snapshot handelt, werden auch diese hauptsächlich aus Zwischenhashes hergestellt und nur die Änderungen einbeziehen, die ein staatenloser Kunde benötigen würde, um den nächsten Block zu beweisen.
Der Code Merkleization zielt darauf ab, diesen riesigen Code -Stück aufzuteilen und das Feld zu ersetzen Codehash In einem Ethereum -Bericht mit der Wurzel eines anderen Merkle -Trie, der treffend das benannt ist Codetrie.
Sein Gewicht in Hashes wert
Schauen wir uns ein Beispiel von ansehen Dieses Video der Ethereum Engineering Groupdie einige Methoden des Codechunkking mit einem analysiert ERC20 Token Vertrag. Da viele der Token, von denen Sie gehört haben, nach dem ERC-20-Standard gemacht werden, ist dies ein guter Kontext der realen Welt, um Code Merkleization zu verstehen.
Weil Bytecode lang und widerspenstig ist, verwenden wir eine einfache Abkürzung, um vier Code -Bytes (8 Hexidezimalzeichen) durch eines zu ersetzen . oder X Das Zeichen, wobei letztere Bytecode darstellen, die für die Ausführung einer bestimmten Funktion erforderlich sind (im Beispiel die ERC20.Transfer () Funktion wird durchgehend verwendet).
In dem ERC20 -Beispiel die Aufruf des Beispiels überweisen() Funktion verwendet etwas weniger als die Hälfte des gesamten Smart -Vertrags:
XXX.XXXXXXXXXXXXXXXXXX.......................................... .....................XXXXXX..................................... ............XXXXXXXXXXXX........................................ ........................XXX.................................XX.. ......................................................XXXXXXXXXX XXXXXXXXXXXXXXXXXX...............XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.................................. .......................................................XXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXX..................................X XXXXXXXX........................................................ ....
Wenn wir diesen Code in Stücke von 64 Bytes aufteilen wollten, müssten nur 19 der 41 Brocken eine Staatelose ausführen überweisen() Transaktion, mit dem Rest der erforderlichen Daten, die von einem Zeugen stammen.
|XXX.XXXXXXXXXXXX|XXXXXX..........|................|................ |................|.....XXXXXX.....|................|................ |............XXXX|XXXXXXXX........|................|................ |................|........XXX.....|................|............XX.. |................|................|................|......XXXXXXXXXX |XXXXXXXXXXXXXXXX|XX..............|.XXXXXXXXXXXXXXX|XXXXXXXXXXXXXXXX |XXXXXXXXXXXXXXXX|XXXXXXXXXXXXXX..|................|................ |................|................|................|.......XXXXXXXXX |XXXXXXXXXXXXXXXX|XXXXXXXXXXXXX...|................|...............X |XXXXXXXX........|................|................|................ |....
Vergleichen Sie das mit 31 von 81 Stücken in einem 32 Byte -Chunking -Schema:
|XXX.XXXX|XXXXXXXX|XXXXXX..|........|........|........|........|........ |........|........|.....XXX|XXX.....|........|........|........|........ |........|....XXXX|XXXXXXXX|........|........|........|........|........ |........|........|........|XXX.....|........|........|........|....XX.. |........|........|........|........|........|........|......XX|XXXXXXXX |XXXXXXXX|XXXXXXXX|XX......|........|.XXXXXXX|XXXXXXXX|XXXXXXXX|XXXXXXXX |XXXXXXXX|XXXXXXXX|XXXXXXXX|XXXXXX..|........|........|........|........ |........|........|........|........|........|........|.......X|XXXXXXXX |XXXXXXXX|XXXXXXXX|XXXXXXXX|XXXXX...|........|........|........|.......X |XXXXXXXX|........|........|........|........|........|........|........ |....
An der Oberfläche scheint es, als wären kleinere Stücke effizienter als größere, weil die Meistens-leer Stücke sind seltener. Aber hier müssen wir uns daran erinnern, dass der nicht verwendete Code auch Kosten hat: Jeder nicht ausgeführte Code-Chunk wird durch einen Hash von ersetzt feste Größe. Kleinere Codebrocken bedeuten eine größere Anzahl von Hashes für den nicht verwendeten Code, und diese Hashes könnten jeweils 32 Bytes (oder so klein wie 8 Bytes) sein. Sie könnten zu diesem Zeitpunkt “Hol” ausrufen! Wenn der Hash von Code -Stücken eine Standardgröße von 32 Bytes ist, wie würde es dann helfen, 32 Bytes Code durch 32 Bytes Hash zu ersetzen? “
Erinnern Sie sich daran, dass der Vertragscode ist Merkleizedwas bedeutet, dass alle Hashes in der miteinander verbunden sind Codetrie – Der Wurzel-Hasch, dessen Block validieren müssen. In dieser Struktur jeder sequentiell Nicht ausgeführte Stücke erfordern nur einen Hash, egal wie viele es gibt. Das heißt, ein Hash kann sich für ein potenziell großes Glied voller sequentieller Chunk -Hashes auf dem Merkleized -Code -Trie einlassen, solange keines von ihnen für die codierte Ausführung benötigt wird.
Wir müssen zusätzliche Daten sammeln
Die Schlussfolgerung, zu der wir gebaut haben, ist ein bisschen ein Antiklimax: Es gibt kein theoretisch “optimales” Schema für den Code Merkleization. Designoptionen wie die Behebung der Größe von Codebrocken und Hashes Abhängig von Daten, die über die “reale Welt” gesammelt wurden. Jeder intelligente Vertrag wird Merkleise unterschiedlich sein, sodass die Forscher die Forscher, das Format auszuwählen, das die größten Effizienzgewinne für die beobachtete Mainnet -Aktivität liefert. Was bedeutet das genau?
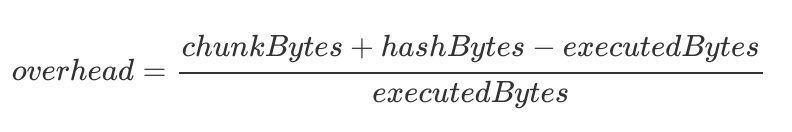
Eine Sache, die angeben könnte, wie effizient ein Code Merkleization -Schema ist Merkleization OverheadDie Frage beantwortet die Frage: “Wie viel zusätzliche Informationen, die über ausgeführten Code hinaus in diesen Zeugen einbezogen werden?”
Schon haben wir einige vielversprechende Ergebnissegesammelt ein speziell gebautes Werkzeug Entwickelt von Horacio Mijail vom Consensys Teamx Research Team, das Gemeinkosten von nur 25% zeigt – überhaupt nicht schlecht!
Kurz gesagt, die Daten zeigen, dass kleinere Stechgrößen mit und largen effizienter sind als größere, insbesondere wenn kleinere Hashes (8 Bytes) verwendet werden. Diese frühen Zahlen sind jedoch keineswegs umfassend, da sie nur etwa 100 jüngste Blöcke darstellen. Wenn Sie dies lesen und an der staatenlosen Ethereum-Initiative beizutragen möchten, indem Sie einen wesentlichen Code-Merkleisierungsdaten sammeln, stellen Sie sich in die Eth1x/2-Forschungsdiskordien in die ethresear.ch-Foren oder den #Code-Merkleization-Kanal auf dem ETH1X/2-Forschungsdiskord vor.
Und wie immer, wenn Sie Fragen, Feedback oder Anfragen im Zusammenhang mit “den 1.x -Dateien” und dem staatenlosen Ethereum, DM oder @Gichiba auf Twitter haben.