
Merkle -Bäume sind ein grundlegender Bestandteil dessen, was Blockchains zum Ticken bringt. Obwohl es definitiv theoretisch möglich ist, eine Blockchain ohne Merkle -Bäume herzustellen, stellt einfach durch die Schaffung von riesigen Blockkopfzeilen, die direkt jede Transaktion enthalten, große Skalierbarkeitsprobleme auf, die die Fähigkeit, auf lange Sicht auf lange Sicht außerhalb der Reichweite der Reichweite der Reichweite zu vertrauen, auf lange Sicht zu vertrauen. Dank Merkle Trees ist es möglich, Ethereum -Knoten zu bauen, die auf allen Computern und Laptops groß und klein, Smartphones und sogar Internet of Things -Geräte wie diejenigen, die von produziert werden, erstellt werden. Slock.it. Wie genau funktionieren diese Merkle -Bäume und welchen Wert bieten sie sowohl jetzt als auch in Zukunft?
Erstens die Grundlagen. Ein Merkle -Baum im allgemeinsten Sinne ist eine Möglichkeit, eine große Anzahl von “Teilen” von Daten zusammen zu haben, die sich auf die Aufteilung der Teile in Eimer angewiesen haben, wobei jeder Eimer nur wenige Teile enthält. Anschließend den Hash der einzelnen Eimer wiederholt und denselben Vorgang wiederholt, so bis die Gesamtzahl der Hashes nur ein Hash -Hash -Hash -Hash -Hader ist.
Die häufigste und einfachste Form des Merkle -Baumes ist der binäre Mekle -Baum, bei dem ein Eimer immer aus zwei angrenzenden Stücken oder Hashes besteht. Es kann wie folgt dargestellt werden:
Was ist der Vorteil dieser seltsamen Art von Hashing -Algorithmus? Warum verkettet nicht einfach alle Stücke zu einem einzigen großen Stück und verwenden Sie einen regulären Hashing -Algorithmus dazu? Die Antwort ist, dass es einen ordentlichen Mechanismus ermöglicht, der als Merkle Proofs bekannt ist:
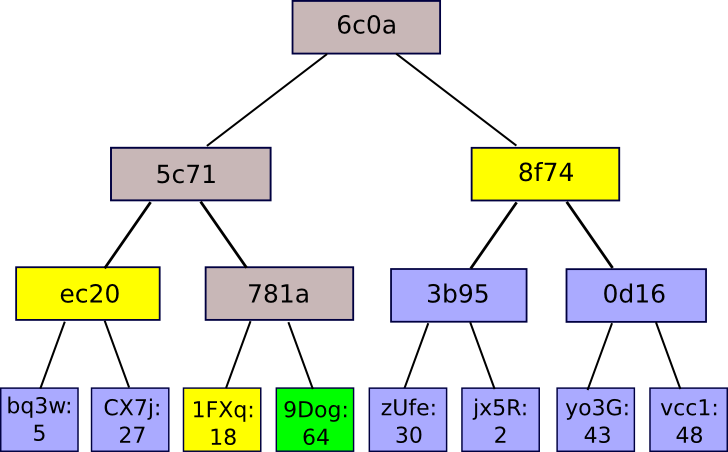
Ein Merkle -Proof besteht aus einem Stück, dem Wurzelhash des Baumes und dem “Zweig”, der aus allen Hashes besteht, die vom Weg vom Stück bis zur Wurzel auf den Weg gehen. Jemand, der den Beweis liest, kann überprüfen, ob der Hashing zumindest für diesen Zweig den ganzen Weg den Baum hinauf ist und daher der angegebene Chunk tatsächlich an dieser Position im Baum ist. Die Anwendung ist einfach: Nehmen wir an, dass es eine große Datenbank gibt und dass der gesamte Inhalt der Datenbank in einem Merkle -Baum gespeichert ist, in dem die Wurzel des Merkle -Baums öffentlich bekannt und vertrauenswürdig ist (z. B. wurde digital von genügend vertrauenswürdigen Parteien signiert, oder es gibt viele Beweise für Arbeiten). Dann kann ein Benutzer, der in der Datenbank eine Schlüsselwerte suchen (z. B. “Sagen Sie mir das Objekt in Position 85273”), kann nach einem Merkle-Beweis bitten und den Beweis erhalten, dass er korrekt ist, und daher der erhaltene Wert Eigentlich ist es In Position 85273 in der Datenbank mit diesem bestimmten Stamm. Es ermöglicht einen Mechanismus zur Authentifizierung a klein Datenmenge, wie ein Hash, um ebenfalls authentifiziert zu werden groß Datenbanken mit potenziell unbegrenzter Größe.
Merkle Proofs in Bitcoin
Die ursprüngliche Anwendung von Merkle Proofs war in Bitcoin, wie von Satoshi Nakamoto 2009 beschrieben und erstellt. Die Bitcoin -Blockchain verwendet Merkle -Proofs, um die Transaktionen in jedem Block zu speichern:
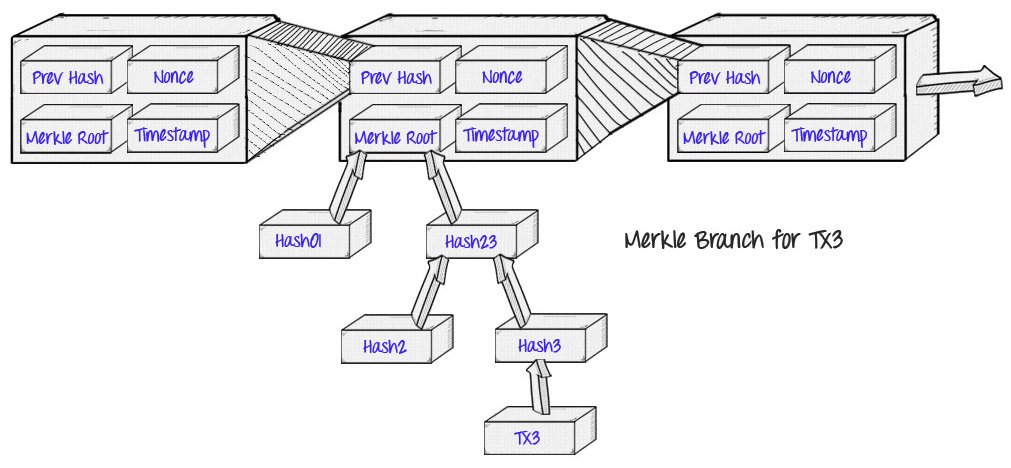
Der Vorteil, den dies bietet, ist das Konzept, das Satoshi als “vereinfachte Zahlungsüberprüfung” bezeichnete: anstatt herunterzuladen jeder Transaktion und jeder Block kann ein “leichter Client” nur die Kette von herunterladen Blockheader80-Byte-Datenbrocken für jeden Block, der nur fünf Dinge enthalten:
- Ein Hash des vorherigen Headers
- Ein Zeitstempel
- Ein Minenschwierigkeitswert
- Ein Nachweis von Arbeit Nonce
- Ein Wurzel -Hash für den Merkle -Baum, der die Transaktionen für diesen Block enthält.
Wenn der leichte Client den Status einer Transaktion bestimmen möchte, kann er einfach nach einem Merkle -Beweis bitten, der zeigt, dass sich eine bestimmte Transaktion in einem der Merkle -Bäume befindet, deren Wurzel in einem Blockkopf für die Hauptkette liegt.
Dies bringt uns ziemlich weit, aber Light-Kunden im Bitcoin-Stil haben ihre Grenzen. Eine besondere Einschränkung ist, dass sie zwar die Aufnahme von Transaktionen nachweisen können, aber nichts über den aktuellen Zustand nachweisen können (z. B. digitale Vermögenswerte, Namensregistrierungen, den Status von Finanzverträgen usw.). Wie viele Bitcoins hast du gerade? Ein Bitcoin Light -Client kann ein Protokoll verwenden, das das Abfragen mehrerer Knoten beinhaltet und darauf vertraut, dass mindestens einer von ihnen Sie über bestimmte Transaktionsausgaben aus Ihren Adressen informiert, und dies bringt Sie für diesen Anwendungsfall ziemlich weit, aber für andere komplexere Anwendungen ist es nicht annähernd ausreichend. Die genaue Natur des Effekts einer Transaktion kann von der Wirkung mehrerer früherer Transaktionen abhängen, die selbst von früheren Transaktionen abhängen, und daher müssten Sie letztendlich jede einzelne Transaktion in der gesamten Kette authentifizieren. Um dies zu umgehen, geht Ethereum das Merkle -Baumkonzept noch einen Schritt weiter.
Merkle -Beweise in Ethereum
Jeder Blockheader in Ethereum enthält nicht nur einen Merkle -Baum, sondern auch einen Merkle -Baum drei Bäume für drei Arten von Objekten:
- Transaktionen
- Einnahmen (im Wesentlichen Datenstücke, die die zeigen Wirkung jeder Transaktion)
- Zustand
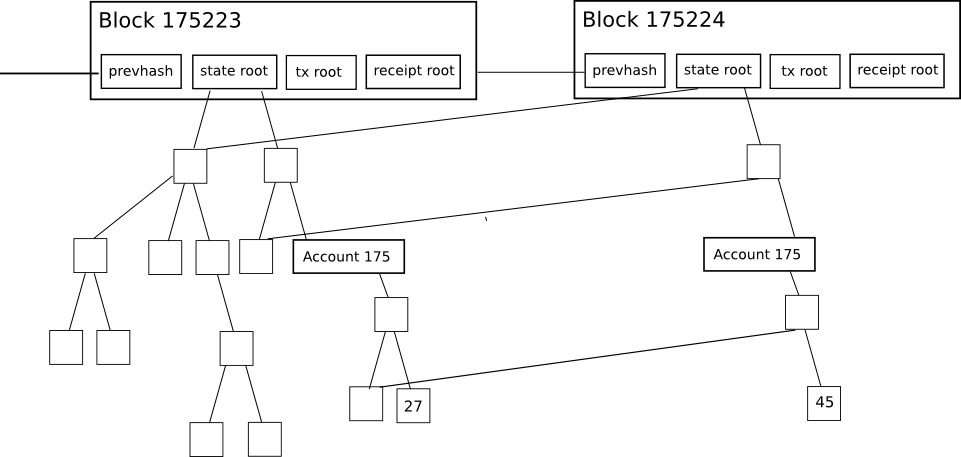
Dies ermöglicht ein hoch fortgeschrittenes Light -Client -Protokoll, mit dem Light -Clients auf viele Arten von Abfragen leicht zu überprüfbaren und überprüfbaren Antworten erhalten können:
- Wurde diese Transaktion in einen bestimmten Block aufgenommen?
- Sagen Sie mir alle Fälle eines Ereignisses vom Typ X (z. B. eines Crowdfunding -Vertrag
- Was ist der aktuelle Kontostand meines Kontos?
- Gibt es dieses Konto?
- Stellen Sie sich vor, diese Transaktion für diesen Vertrag durchzuführen. Was wäre die Ausgabe?
Der erste wird vom Transaktionsbaum behandelt; Der dritte und vierte wird vom Staatsbaum und der zweite vom Quittungsbaum behandelt. Die ersten vier sind ziemlich einfach zu berechnen; Der Server findet einfach das Objekt, holt den Merkle -Zweig (die Liste der Hashes, die vom Objekt zum Baumwurzel steigen) und antwortet mit dem Zweig auf den leichten Client.
Der fünfte wird auch vom Staatsbaum behandelt, aber die Art und Weise, wie er berechnet wird, ist komplexer. Hier müssen wir konstruieren, was genannt werden kann Merkle State Transition Beweis. Im Wesentlichen ist es ein Beweis, der die Behauptung ausmacht, “wenn Sie Transaktion ausführen T im Zustand mit Wurzel SDas Ergebnis wird ein Zustand mit Wurzel sein S’mit Protokoll L und Ausgabe O“(” Output “existiert als Konzept in Ethereum, da jede Transaktion ein Funktionsaufruf ist; es ist nicht theoretisch notwendig).
Um den Beweis zu berechnen, erstellt der Server lokal einen gefälschten Block, legt den Status auf S fest und gibt vor, während der Anwendung der Transaktion ein leichter Client zu sein. Das heißt, wenn der Prozess der Anwendung der Transaktion den Client erfordert, dass der Saldo eines Kontos festgelegt wird, macht der leichte Client eine Saldo -Abfrage. Wenn der leichte Kunde einen bestimmten Artikel in der Speicherung eines bestimmten Vertrags überprüfen muss, macht der leichte Kunde eine Abfrage dafür und so weiter. Der Server “antwortet” auf alle seine eigenen Abfragen korrekt, verfolgt jedoch alle Daten, die er zurücksendet. Der Server sendet dem Client dann die kombinierten Daten aus allen diesen Anforderungen als Beweis. Der Kunde führt dann genau das gleiche Verfahren durch, aber Verwenden des bereitgestellten Beweises als Datenbank; Wenn sein Ergebnis das gleiche entspricht, wie der Server behauptet, akzeptiert der Client den Nachweis.
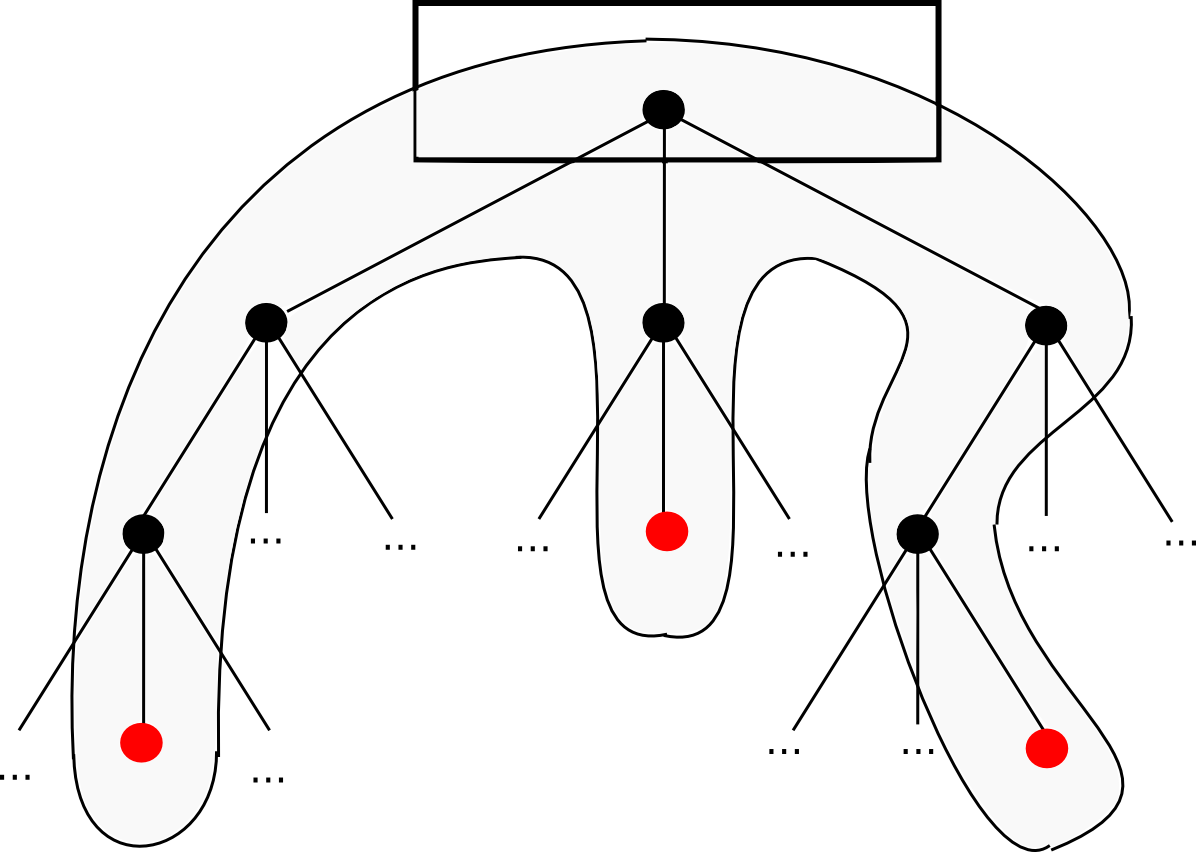
Patricia Bäume
Es wurde oben erwähnt, dass die einfachste Art von Merkle -Baum der binäre Merkle -Baum ist; Die in Ethereum verwendeten Bäume sind jedoch komplexer – dies ist der “Merkle Patricia Tree”, von dem Sie in unserer Dokumentation hören. Dieser Artikel wird nicht in die detaillierte Spezifikation eingehen. das wird am besten durch gemacht von Dieser Artikel Und Dieses hierobwohl ich die grundlegende Argumentation diskutieren werde.
Binäre Merkle -Bäume sind sehr gute Datenstrukturen für die Authentifizierung von Informationen, die sich in einem “List” -Format befinden. Im Wesentlichen eine Reihe von Stücken nacheinander. Für Transaktionsbäume sind sie auch gut, weil es keine Rolle spielt, wie viel Zeit es braucht bearbeiten Ein Baum, sobald er erzeugt ist, da der Baum einmal erzeugt und dann für immer fest gefroren ist.
Für den Staatsbaum ist die Situation jedoch komplexer. Der Staat in Ethereum besteht im Wesentlichen aus einer Schlüsselwertkarte, in der die Schlüssel Adressen und die Werte für Kontoerklärungen sind, wobei der Gleichgewicht, Nonce, Code und Speicher für jedes Konto aufgeführt ist (wobei der Speicher selbst ein Baum ist). Zum Beispiel sieht der Morden TestNet Genesis -Zustand wie folgt aus:
{
"0000000000000000000000000000000000000001": {
"balance": "1"
},
"0000000000000000000000000000000000000002": {
"balance": "1"
},
"0000000000000000000000000000000000000003": {
"balance": "1"
},
"0000000000000000000000000000000000000004": {
"balance": "1"
},
"102e61f5d8f9bc71d0ad4a084df4e65e05ce0e1c": {
"balance": "1606938044258990275541962092341162602522202993782792835301376"
}
}
Im Gegensatz zur Transaktionsgeschichte muss der Staat jedoch häufig aktualisiert werden: Der Restbetrag und die Nicht -Cones -Konten werden häufig geändert, und was mehr ist, werden häufig neue Konten eingefügt, und die Schlüssel im Speicher werden häufig eingefügt und gelöscht. Was also gewünscht wird, ist eine Datenstruktur, in der wir das neue Baumwurzel nach einem Einfügen, Aktualisieren oder Löschen des Betriebs schnell berechnen können, ohne den gesamten Baum neu zu berechnen. Es gibt auch zwei äußerst wünschenswerte Sekundäreigenschaften:
- Die Tiefe des Baumes ist begrenzt, selbst wenn ein Angreifer absichtlich Transaktionen erstellt, um den Baum so tief wie möglich zu machen. Andernfalls könnte ein Angreifer eine Ablehnung des Dienstangriffs ausführen, indem der Baum so tief ist, dass jedes individuelle Update extrem langsam wird.
- Die Wurzel des Baumes hängt nur von den Daten ab, nicht von der Reihenfolge, in der Aktualisierungen vorgenommen werden. Das Erstellen von Updates in einer anderen Reihenfolge und sogar die Neuzunahme des Baumes von Grund auf sollte die Wurzel nicht ändern.
Der Patricia TreeIn einfachen Worten ist es vielleicht der nächste, dass wir alle diese Eigenschaften gleichzeitig erreichen können. Die einfachste Erklärung dafür, wie es funktioniert, ist, dass der Schlüssel, unter dem ein Wert gespeichert wird, in den “Pfad” codiert wird, dass Sie den Baum abnehmen müssen. Jeder Knoten hat 16 Kinder Hund hex codiert ist 6 4 6 15 6 7 7Sie würden also mit der Wurzel beginnen, das 6. Kind hinuntergehen, dann das vierte und so weiter, bis Sie das Ende erreichen. In der Praxis gibt es einige zusätzliche Optimierungen, die wir vornehmen können, um den Prozess viel effizienter zu gestalten, wenn der Baum spärlich ist, aber das ist das Grundprinzip. Die beiden Artikel erwähnt über Beschreiben Sie alle Funktionen viel detaillierter.