
Eines der wichtigsten Probleme, die im Verlauf der olympischen Stressnetzveröffentlichung angesprochen wurden, ist die große Menge an Daten, die Kunden zum Speichern benötigen. Über etwas mehr als drei Monate des Betriebs und insbesondere im letzten Monat hat sich die Datenmenge in den Blockchain-Ordner jedes Ethereum-Kunden auf beeindruckende 10-40 Gigabyte gestoßen, je nachdem, welcher Client Sie verwenden und ob die Komprimierung aktiviert ist oder nicht. Obwohl es wichtig ist zu beachten, dass dies in der Tat ein Stresstestszenario ist, in dem Benutzer dazu angeregt werden, Transaktionen auf der Blockchain zu entsorgen, die nur den kostenlosen Test als Transaktionsgebühr bezahlen, sind die Transaktionsdurchsatzstufen daher mehrmals höher als Bitcoin, aber es ist dennoch ein legitimes Sorge für Benutzer, die in vielen Fällen Hunderte von Gigabyten haben, um sich zu erfreuen, um sich auf das Lagern zu erfreuen.
Lassen Sie uns zunächst untersuchen, warum die aktuelle Ethereum -Client -Datenbank so groß ist. Ethereum hat im Gegensatz zu Bitcoin die Eigenschaft, dass jeder Block etwas enthält, das als “Zustandswurzel” bezeichnet wird: der Wurzel -Hash von a Spezialart von Merkle Tree Dies speichert den gesamten Status des Systems: Alle Kontos, Vertragspeicher, Vertragscode und Konto -Noncen sind im Inneren.
Der Zweck davon ist einfach: Es ermöglicht einen Knoten, der nur den letzten Block angegeben hat, zusammen mit einer gewissen Sicherheit, dass der letzte Block tatsächlich der jüngste Block ist, um mit der Blockchain extrem schnell zu “synchronisieren”, ohne historische Transaktionen zu verarbeiten, indem der Rest des Baumes einfach von den Knoten im Netzwerk heruntergeladen wird (die vorgeschlagenen Transaktionen Hashlookup Drahtprotokollnachricht wird dies erleichtern) und überprüfen, ob der Baum korrekt ist, indem er überprüft, ob alle Hashes übereinstimmen und dann von dort aus fortgeführt werden. In einem vollständig dezentralen Kontext wird dies wahrscheinlich durch eine fortgeschrittene Version der Bitcoin-Header-First-Reverication-Strategie erfolgen, die ungefähr wie folgt aussieht:
- Laden Sie so viele Block -Header herunter, wie der Kunde in die Hände bekommen kann.
- Bestimmen Sie den Header, der sich am Ende der längsten Kette befindet. Gehen Sie von diesem Kopfzeile aus, um sicher von 100 Blocks zurückzukehren und rufen Sie den Block an dieser Position P an P an100(H) (“der Großeltern der Hundertth Generation des Kopfes”)
- Laden Sie den Staatsbaum von der staatlichen Wurzel von P herunter100(H) mit der Hashlookup OPCODE (Beachten Sie, dass dies nach den ersten ein oder zwei Runden bei so vielen Gleichaltrigen wie gewünscht parallelisiert werden kann. Stellen Sie sicher, dass alle Teile des Baumes übereinstimmen.
- Gehen Sie von dort aus normal fort.
Für leichte Clients ist die staatliche Wurzel noch vorteilhafter: Sie können den genauen Saldo und den Status eines Kontos sofort bestimmen, indem sie einfach das Netzwerk für die Netzwerk fragen ein bestimmter Zweig des Baumes, ohne Bitcoins mehrstufige 1-von-n-“-An-N-” -Anfragen nach allen Transaktionsausgängen zu befolgen, dann fordern Sie alle Transaktionen an, um diese Ausgänge auszugeben, und nehmen Sie das restliche “Light-Client-Modell ein.
Dieser Staatsbaummechanismus hat jedoch einen wichtigen Nachteil, wenn es naiv umgesetzt wird: Die Zwischenknoten im Baum erhöhen die Menge an Speicherplatz erheblich, um alle Daten zu speichern. Um zu sehen, warum, betrachten Sie dieses Diagramm hier:
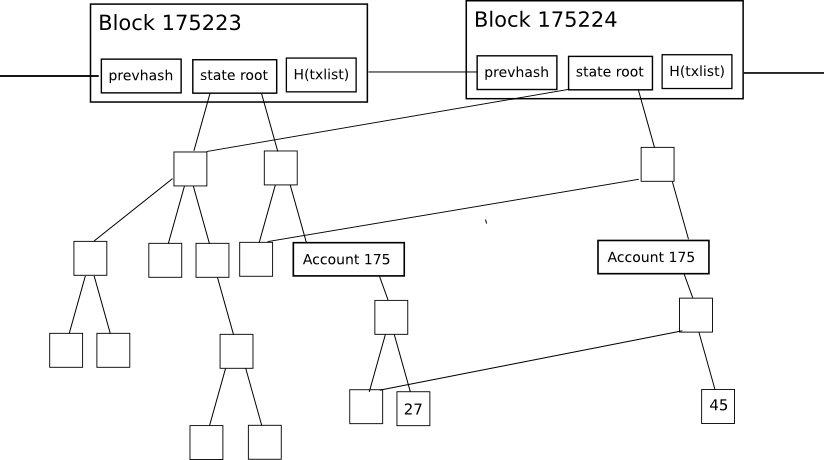
Die Änderung des Baumes während jedes einzelnen Blocks ist ziemlich klein, und die Magie des Baumes als Datenstruktur besteht darin, dass die meisten Daten einfach zweimal referenziert werden können, ohne kopiert zu werden. Trotzdem müssen für jede Änderung des Zustands, der vorgenommen wird, eine logarithmisch große Anzahl von Knoten (dh ~ 5 bei 1000 Knoten, ~ 10 bei 1000000 Knoten, ~ 15 bei 1000000000 Knoten) zweimal gespeichert werden, eine Version für den alten Baum und eine Version für den neuen Tries. Schließlich können wir, wenn ein Knoten jeden Block verarbeitet O (n*log (n))Wo N ist die Transaktionslast. In praktischer Hinsicht beträgt die Ethereum-Blockchain nur 1,3 Gigabyte, aber die Größe der Datenbank einschließlich all dieser zusätzlichen Knoten beträgt 10-40 Gigabyte.
Also, was können wir tun? Eine rückwärts gerichtete Lösung besteht darin, einfach die Header-First-Synchronisierungen zu implementieren, im Wesentlichen den Festplattenverbrauch neuer Benutzer auf Null zurückzusetzen und Benutzer ihren Festplattenverbrauch niedrig zu halten, indem sie alle ein oder zwei Monate neu synchronisiert werden, aber das ist eine etwas hässliche Lösung. Der alternative Ansatz ist die Implementierung State Tree Beschneiden: Verwenden Sie im Wesentlichen Referenzzählung Um zu verfolgen, wann Knoten im Baum (hier “Knoten” im Computer-Science-Begriff verwendet werden, bedeutet “Datenstück, das sich irgendwo in einer Grafik oder in einer Baumstruktur befindet”, nicht “Computer im Netz X Blöcke (z. X = 5000) Nach dieser Anzahl der Blöcke sollte der Knoten dauerhaft aus der Datenbank gelöscht werden. Im Wesentlichen speichern wir die Baumknoten, die Teil des aktuellen Zustands sind, und wir speichern sogar die jüngste Geschichte, aber wir speichern keine Geschichte über 5000 Blöcke.
X sollte so niedrig wie möglich eingestellt werden, um den Raum zu sparen, aber einzustellen X Zu niedrige Kompromisse von Robustheit: Sobald diese Technik implementiert ist, kann ein Knoten nicht mehr zurückkehren als X Blöcke ohne die Synchronisation im Wesentlichen vollständig neu zu starten. Lassen Sie uns nun sehen, wie dieser Ansatz unter Berücksichtigung aller Eckfälle vollständig implementiert werden kann:
- Bei der Bearbeitung eines Blocks mit Zahl NVerfolgen Sie alle Knoten (im Zustand, Baum und Quittungsbäume), deren Referenzzahl auf Null fällt. Legen Sie die Hashes dieser Knoten in eine “Todeszeile” -Datenbank in eine Art Datenstruktur, damit die Liste später nach der Blocknummer abgerufen werden kann (insbesondere die Blocknummer N + x) und markieren Sie den Knotendatenbankeintrag selbst als löschend im Block N + x.
- Wenn ein Knoten in der Todeszeile erneut installiert wird (ein praktisches Beispiel hierfür ist ein Rechenschaft Fund dann zu einem anderen Wert umschalten Gund dann Konto b erwerben Staat F Während der Knoten für F ist in der Todeszelle) und erhöhen Sie dann seine Referenzzahl auf einen zurück. Wenn dieser Knoten in einem zukünftigen Block erneut gelöscht wird M (mit M> nnicht M + x.
- Wenn Sie zum Verarbeitungsblock kommen N + xErinnern Sie sich an die Liste der Hashes, die Sie während des Blocks zurückgelegt haben N. Überprüfen Sie den mit jedem Hash zugeordneten Knoten. Wenn der Knoten noch für das Löschen markiert ist während dieses bestimmten Blocks (dh nicht wieder hergestellt und vor allem nicht wieder eingestellt und dann für das Löschen neu markiert später), löschen Sie es. Löschen Sie auch die Liste der Hashes in der Datenbank für die Todeszeile.
- Manchmal befindet sich der neue Kopf einer Kette nicht auf dem vorherigen Kopf und Sie müssen einen Block zurückversetzen. In diesen Fällen müssen Sie in der Datenbank ein Journal aller Änderungen an Referenzzählungen aufbewahren (das ist “Journal” wie in Journaling -Dateisysteme; im Wesentlichen eine geordnete Liste der vorgenommenen Änderungen); Wenn Sie einen Block zurückkehren, löschen Sie die bei der Erzeugung dieses Blocks erzeugte Todeszeileliste und schließen Sie die gemäß dem Journal vorgenommenen Änderungen (und löschen Sie das Journal, wenn Sie fertig sind).
- Löschen Sie bei der Bearbeitung eines Blocks das Journal am Block N – x; Sie sind nicht in der Lage, mehr zurückzukehren als X Blöcke sowieso, das Journal ist also überflüssig (und wenn sie gehalten werden, würde es tatsächlich den ganzen Punkt des Beschneidens besiegen).
Sobald dies erledigt ist, sollte die Datenbank nur staatliche Knoten gespeichert werden, die den letzten verknüpften X Blöcke, so dass Sie immer noch alle Informationen haben, die Sie aus diesen Blöcken benötigen, aber nichts weiter. Darüber hinaus gibt es weitere Optimierungen. Besonders danach X Blöcke, Transaktions- und Quittungsbäume sollten vollständig gelöscht werden, und sogar Blöcke können auch gelöscht werden – obwohl es ein wichtiges Argument für eine Teilmenge von “Archivknoten” gibt, die absolut alles speichern, um dem Rest des Netzwerks zu helfen, die Daten zu erwerben, die sie benötigt.
Wie viel Einsparungen können uns das geben? Wie sich herausstellt, ziemlich viel! Insbesondere wenn wir die ultimative Daredevil -Route nehmen und gehen X = 0 (dh. Verlieren Sie absolut alle Fähigkeiten, selbst Single -Block -Gabeln zu handhaben und keine Geschichte zu speichern. Konten wie diese mit Speicherschläfen gefüllt, um das Netzwerk absichtlich zu spam. Bei X = 100000Wir würden im Wesentlichen die aktuelle Größe von 10 bis 40 Gigabyte erhalten, da der größte Teil des Wachstums in den letzten hunderttausend Blöcken stattfand und der zusätzliche Platz für die Aufbewahrung von Zeitschriften und die Listen für die Todesteile den Rest des Unterschieds ausmachen würde. Bei jedem Wert dazwischen können wir erwarten, dass das Scheibenraumwachstum linear ist (dh. X = 10000 würde uns ungefähr neunzig Prozent des Weges dorthin nach fast Null bringen).
Beachten Sie, dass wir vielleicht eine hybride Strategie verfolgen möchten: Alle behalten Block aber nicht alle Zustandsbaumknoten; In diesem Fall müssten wir ungefähr 1,4 Gigabyte hinzufügen, um die Blockdaten zu speichern. Es ist wichtig zu beachten, dass die Ursache der Blockchain -Größe keine schnellen Blockzeiten ist. Derzeit bestimmen die Blockkopfzeile der letzten drei Monate ungefähr 300 Megabyte, und der Rest sind Transaktionen des letzten Monats. Bei hohem Nutzungsniveau können wir weiter erwarten, dass Transaktionen weiterhin dominieren. Allerdings müssen leichte Kunden auch Blockkopfzeile beschneiden, um unter schlechten Umständen zu überleben.
Die oben beschriebene Strategie wurde in einer sehr frühen Alpha -Form in umgesetzt Pyeth; Es wird in allen Kunden zu gegebener Zeit nach Frontier-Start ordnungsgemäß implementiert, da eine solche Lagerung nur ein mittelfristiges und kein kurzfristiges Skalierbarkeitsanliegen ist.